
This content originally appeared on Level Up Coding - Medium and was authored by Arpit Jindal
In the rapidly evolving field of artificial intelligence, generative models have gained significant traction due to their ability to produce coherent and contextually relevant text. Among these models, the transformer architecture stands out as a groundbreaking innovation, enabling the development of powerful large language models (LLMs) like OpenAI’s GPT series, Google’s BERT, and many others. This article delves into the intricacies of transformer architecture, its role in generative AI, and its impact on the development of LLMs.
Traditional Approaches and their Limitations
Before transformers, recurrent neural networks (RNNs), specifically Long Short-Term Memory (LSTM) networks, were the dominant architecture for NLP tasks. LSTMs excel at capturing sequential information but struggle with long-range dependencies. Imagine reading a sentence — understanding the meaning of a word like “river” might depend on another word far away in the sentence, like “bridge.” LSTMs have difficulty modeling these long-range relationships, limiting their effectiveness in complex language tasks.
Understanding Transformer Architecture
Introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017, the transformer architecture revolutionized natural language processing (NLP). Unlike its predecessors, such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), transformers do not rely on sequential data processing. Instead, they leverage a mechanism known as self-attention to process input data in parallel, significantly enhancing computational efficiency and model performance.
Key Components of Transformer Architecture
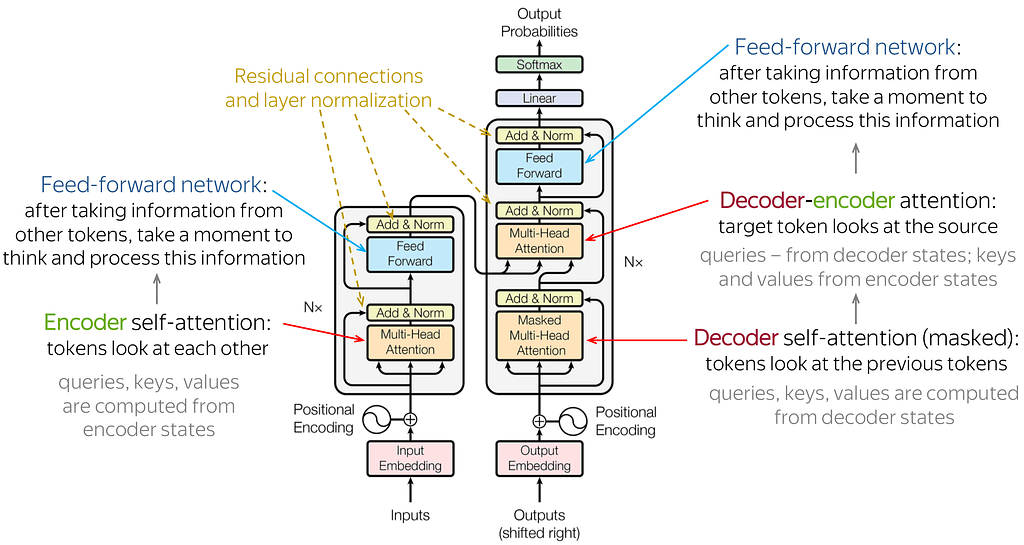
At the core of Transformers lies the self-attention mechanism, which analyzes word relationships in a sentence. Unlike traditional sequential processing, Transformers consider all words at once. To understand word order, positional encoding is added. Multi-head attention further enhances comprehension by examining the sentence from different angles. Encoder and decoder stacks handle input processing and output generation, respectively. Normalization and residual connections ensure a smooth training process. These components working together make Transformers powerful for natural language tasks.
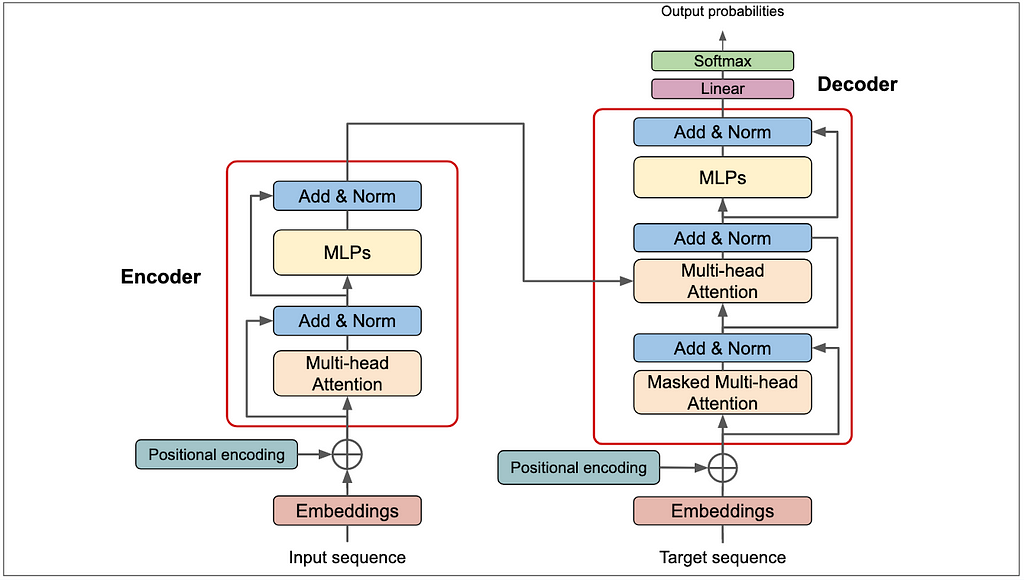

- Tokenization: Tokenization is the most basic step. It consists of a large dataset of tokens, including all the words, punctuation signs, etc. The tokenization step takes every word, prefix, suffix, and punctuation signs, and sends them to a known token from the library.

- Embedding: Once the input has been tokenized, it’s time to turn words into numbers. For this, we use an embedding. If two pieces of text are similar, then the numbers in their corresponding vectors are similar to each other (componentwise, meaning each pair of numbers in the same position are similar). Otherwise, if two pieces of text are different, then the numbers in their corresponding vectors are different.

- Positional Encoding: Since transformers do not inherently understand the order of words, positional encoding is introduced to provide the model with information about the position of each word in a sequence. This is done by adding a unique positional vector to each word embedding.
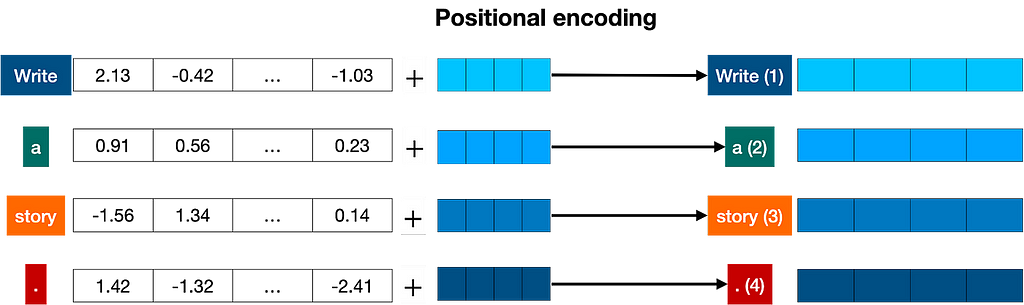
- Self-Attention Mechanism: The self-attention mechanism allows the model to weigh the importance of different words in a sentence relative to each other. This is achieved by computing three vectors for each word: Query (Q), Key (K), and Value (V). These vectors are used to calculate attention scores, determining how much focus each word should receive when generating a response.
- Multi-Head Attention: To capture different types of relationships and dependencies in the data, transformers employ multi-head attention. This involves running several self-attention mechanisms in parallel (each with different parameter sets), allowing the model to consider information from multiple perspectives simultaneously.
- Feed-Forward Neural Networks: After the attention mechanism, the transformer applies a feed-forward neural network to each position separately and identically. This helps in transforming the data into a more useful representation for the subsequent layers.
- Layer Normalization and Residual Connections: Layer normalization and residual connections are employed to stabilize and improve the training of deep networks. Residual connections help in mitigating the vanishing gradient problem by allowing gradients to flow through the network more effectively.
- Encoder-Decoder Structure: The original transformer model uses an encoder-decoder structure. The encoder processes the input sequence and generates a set of hidden representations. The decoder takes these representations and generates the output sequence, one word at a time.
The Transformer’s Powerhouse: The Attention Mechanism
The transformer architecture revolutionized NLP by introducing the attention mechanism. This ingenious concept allows the model to focus on specific parts of the input sequence that are relevant to the current element being processed. Just like you focus on important words while reading a sentence, the attention mechanism directs the model’s attention to crucial parts of the input.
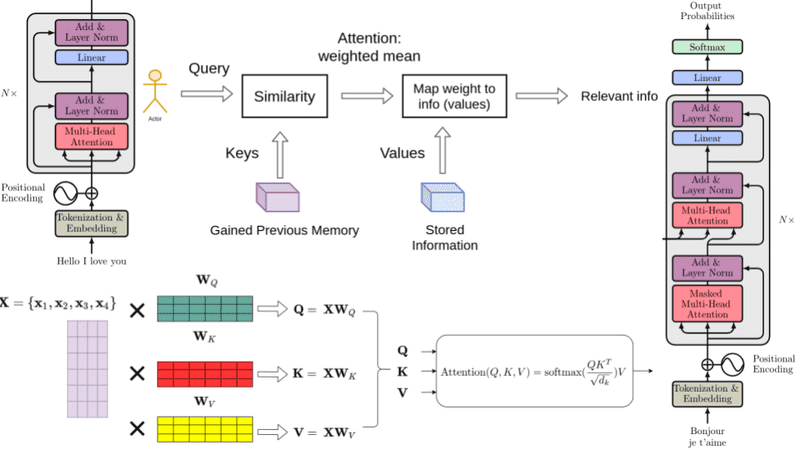
Here’s a deeper dive into how attention works:
- Query, Key, and Value Vectors: Each element in the sequence is represented by three vectors: a “query” vector representing the current element, a “key” vector for each element in the sequence, and a “value” vector also for each element.
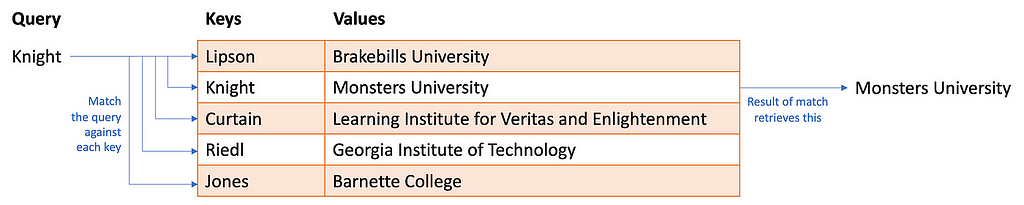
- Attention Scores: The model calculates an “attention score” for each element in the sequence. This score is computed by comparing the query vector with each key vector. High scores indicate a strong relevance between the current element (query) and another element (key) in the sequence. Self-attention works a bit like a fuzzy hash table. You provide a query and instead of looking for an exact match with a key, it finds approximate matches based on the similarity between the query and key. But what if the match isn’t a perfect match? It returns some fraction of the value. Well, this only makes sense if the query, keys, and values are all numerical. Which they are:
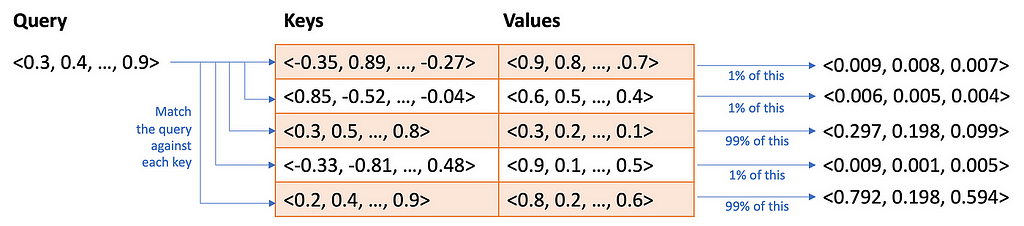
- Weighted Values: The attention scores are used to weight the corresponding value vectors. Essentially, the model pays more attention to the value vectors of elements with higher attention scores, effectively amplifying the contribution of relevant information.
- Attention Output: The weighted value vectors are then summed to create a context vector, which represents the current element’s context based on the relevant parts of the sequence.
There are several advantages to the attention mechanism:
- Capturing Long-Range Dependencies: Unlike RNNs, transformers can effectively model relationships between distant parts of the sequence through the attention mechanism.
- Parallelization: The attention mechanism allows for parallel processing of elements in the sequence, making transformers faster to train compared to RNNs.
- Scalability: Transformers can be scaled to handle massive amounts of data by adding more layers, crucial for training powerful LLMs.
Building Powerful LLMs with Transformers
LLMs are essentially large transformer models pre-trained on vast amounts of text data. This pre-training allows the model to learn general language patterns and representations. Then, LLMs can be fine-tuned for specific tasks, like text generation, translation, or question answering.
Here’s a breakdown of the LLM training process:
- Pre-training: The transformer model is trained on large text corpora using unsupervised learning objectives like masked language modeling or next sentence prediction. These objectives help the model learn relationships between words and sentences in a general sense.
- Fine-tuning: The pre-trained transformer is then fine-tuned for a specific task. This involves adding a task-specific output layer and training the model on labeled data relevant to the desired task.
The transformer’s ability to handle long-range dependencies and its scalability through attention make it ideal for building LLMs. These models can analyze massive amounts of text data, uncovering complex relationships and nuances of language.
Applications in Large Language Models
- GPT (Generative Pre-trained Transformer): OpenAI’s GPT series exemplifies the application of transformer architecture in generative AI. GPT models are trained on vast corpora of text data and fine-tuned for specific tasks, enabling them to generate coherent and contextually appropriate text based on a given prompt.
- BERT (Bidirectional Encoder Representations from Transformers): Although BERT is primarily designed for understanding and encoding text rather than generating it, its architecture has influenced many generative models. BERT’s bidirectional approach allows the model to understand context from both directions, enhancing its comprehension capabilities.
- T5 (Text-to-Text Transfer Transformer): Google’s T5 model treats every NLP task as a text-to-text problem, leveraging the transformer architecture to generate text for a wide range of applications, from translation to summarization.
Impact on Natural Language Processing
The transformer architecture has significantly advanced the field of NLP, enabling the development of models that perform exceptionally well on a variety of tasks. These advancements include:
- Enhanced Language Understanding: Transformers have improved the ability of models to understand and generate human language, making interactions with AI more natural and intuitive.
- Scalability: The parallel processing capability of transformers allows for the training of extremely large models, leading to unprecedented performance on complex language tasks.
- Transfer Learning: Pre-trained transformer models can be fine-tuned for specific tasks, reducing the need for extensive labeled data and computational resources.
Beyond Generative AI: The Versatility of Transformers
While transformers are superstars in generative AI and LLMs, their applications extend far beyond. Their ability to capture long-range dependencies makes them valuable for various NLP tasks, including:
- Sentiment Analysis: Classifying the sentiment (positive, negative, or neutral) of text data.
- Text Summarization: Condensing lengthy text passages into concise summaries.
- Machine Translation: Translating text from one language to another.
Additionally, researchers are exploring the use of transformers in other domains like:
- Image Recognition: Analyzing relationships between different parts of an image for object detection and scene understanding.
- Time Series Forecasting: Identifying patterns and dependencies in time-series data for prediction tasks.
Challenges and Limitations
Despite their success, transformers face challenges:
- Computational Cost: Training large transformers requires significant computational resources.
- Memory Usage: The self-attention mechanism’s memory requirement grows quadratically with the input sequence length.
Future Directions
Ongoing research aims to address these challenges:
- Architectural Enhancements: Researchers are exploring modifications to improve efficiency and reduce resource consumption.
- Ethical Considerations: As transformers become more powerful, ensuring their responsible use and mitigating biases are crucial.
Conclusion
The transformer architecture has revolutionized generative AI and the development of large language models. Its innovative use of self-attention mechanisms, multi-head attention, and parallel processing has set a new standard in natural language processing. As AI continues to evolve, transformers will undoubtedly remain a cornerstone of advancements in generative models, pushing the boundaries of what is possible in machine understanding and generation of human language.
References
- https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- https://mark-riedl.medium.com/a-very-gentle-introduction-to-large-language-models-without-the-hype-5f67941fa59e
- https://medium.com/@amanatulla1606/transformer-architecture-explained-2c49e2257b4c
- https://deeprevision.github.io/posts/001-transformer/
- https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html
Unveiling the Transformer: Powering Generative AI and LLMs was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Arpit Jindal
Arpit Jindal | Sciencx (2024-06-18T20:01:44+00:00) Unveiling the Transformer: Powering Generative AI and LLMs. Retrieved from https://www.scien.cx/2024/06/18/unveiling-the-transformer-powering-generative-ai-and-llms/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.