
This content originally appeared on Level Up Coding - Medium and was authored by Vasukumar Palanisamy
Building a PDF chatbot system, using the Google Gemini Pro large language model.

The large language models are creating a huge impact on human life. It is widely used in every field to solve a problem in everyday human life. The PDF chatbot system will be very useful for education and some other fields.
In this system workflow, the embedding-001 model is going to be used for PDF text embedding, and the Gemini Pro is used for content generation from PDF embeddings. The Google Gemini Pro is a multimodal LLM developed by the Google Deep Mind team.
To learn more about the Gemini Pro model
Building a Text generation and Image captioning models with Google Gemini (using Streamlit)
Embeddings:
To understand about this model workflow, we need to be familiar with the concept of embeddings. The embedding technique is a method of data preprocessing for LLM models. The embedding is crucial thing to build or interact with the LLM models. In this process, the text data are converted into small chunks or tokens.
Then the chunks or tokens are converted into continuous vector representations that capture their semantic meanings in a high-dimensional space. To simply put it, embedding means converting text data into numerical form (vectorization).
The LLM models are trained on this vectorized data and also learn to capture relationships between words, like synonyms or analogies. This model also gained the knowledge to understand the context both syntactically and semantically.
How it is works
This LLM model uses encoder and decoder parts in their pipeline; these parts are used to convert the text into embeddings and embeddings into text. In the first part of this model workflow, the text of the PDF files is vectorized (embedded).
Then your questions based on the PDF document are also embedded for model understanding; the embedded vector values are compared with the PDF vector values, and the more similar values are generated as an output. Here, the models use “cosine similarity” to find content that is very related to the input question.
Let’s start the tutorial
Before writing the code, we have to generate the Gemini API key using the following link:
To generate an API key: https://aistudio.google.com/
To write code, you can use VS Code or the Jupyter notebook text editor.
The first step to building the system is to install the libraries. After that, we have to import the necessary modules from the installed libraries.
#requirements.txt
import streamlit as st
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
from langchain_google_genai import GoogleGenerativeAIEmbeddings
import google.generativeai as genai
from langchain.vectorstores import FAISS
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.chains.question_answering import load_qa_chain
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv
import time
The following code is used to integrate the API key with your environment, in order to use the Gemini Pro model.
load_dotenv()
genai.configure(api_key=os.getenv("GOOGLE_API_KEY"))
The following “get_pdf_text” function takes the PDF files as arguments. Here, the system supports more than one PDF file. The text words are extracted from the given PDF files.
def get_pdf_text(pdf_docs):
text = ""
for pdf in pdf_docs:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
The “get_text_chunks” function takes text as an argument. The RecursiveCharacterTextSplitter module is used to split the large text into smaller chunks.
The chunk_size specifies the maximum size of each chunk. In this case, chunk_size=10000 means each chunk can have up to 10,000 characters. Then the chunk_overlap=1000 means that the last 1,000 characters of one chunk will be repeated as the first 1,000 characters of the next chunk.
def get_text_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000, chunk_overlap=1000)
chunks = text_splitter.split_text(text)
return chunks
The “get_vector_store” function takes the chunks as arguments; the chunks are embedded using the embedding-001 model. Here, the embedded chunks are stored in a vector store locally.
def get_vector_store(text_chunks):
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
# Split text_chunks into smaller batches to avoid timeout
batch_size = 5 # Adjust the batch size as needed
vector_store = None
for i in range(0, len(text_chunks), batch_size):
batch_chunks = text_chunks[i:i + batch_size]
for attempt in range(3): # Retry up to 3 times
try:
if vector_store is None:
vector_store = FAISS.from_texts(batch_chunks, embedding=embeddings)
else:
new_vectors = FAISS.from_texts(batch_chunks, embedding=embeddings)
vector_store.merge(new_vectors)
break # Exit retry loop if successful
except Exception as e:
if attempt < 2: # Wait and retry
time.sleep(5) # Adjust the wait time as needed
else:
st.error(f"Failed to embed batch {i//batch_size + 1}: {e}")
return
if vector_store:
vector_store.save_local("faiss_index")
The “get_conversational_chain” function is used to set up a conversational AI chain using a specific model and a prompt template for generating answers based on the provided context.
The prompt_template string defines how the AI should structure its response. The template includes placeholders {context} and {question}, which will be replaced by the actual context and question when the function is called.
Here, the Google Gemini Pro model is initiated with 0.3 temperature. The temperature parameter controls the randomness of the model’s responses. Lower temperatures result in more deterministic responses.
def get_conversational_chain():
prompt_template = """
Answer the question as detailed as possible from the provided context, make sure to provide all the details. If the answer is not in
the provided context, just say, "answer is not available in the context." Don't provide the wrong answer.
Context:
{context}
Question:
{question}
Answer:
"""
model = ChatGoogleGenerativeAI(model="gemini-pro", temperature=0.3)
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
chain = load_qa_chain(model, chain_type="stuff", prompt=prompt)
return chain
The following “user_input” function takes user input as an argument, and the embedding-001 model is used again to embed the user input. Then, the embedded user input is compared with values in the vector database by using the similarity search function. The relevant content of the question is generated from the vector database.
def user_input(user_question):
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
new_db = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)
docs = new_db.similarity_search(user_question)
chain = get_conversational_chain()
response = chain({"input_documents": docs, "question": user_question}, return_only_outputs=True)
st.write("Reply: ", response["output_text"])
The last step in the process is creating the user interface for the system; here we are using the streamlit package to create that. The above-mentioned functions are integrated with the streamlit package; it takes input from users, and the relevant content is generated from the embedded PDF files.
def main():
st.set_page_config(page_title="Chat with PDF")
st.header("Chat with PDF using Gemini")
user_question = st.text_input("Ask a Question from the PDF Files")
if user_question:
user_input(user_question)
with st.sidebar:
st.title("Menu:")
pdf_docs = st.file_uploader("Upload your PDF Files", accept_multiple_files=True, type=["pdf"])
if st.button("Submit & Process"):
with st.spinner("Processing..."):
try:
raw_text = get_pdf_text(pdf_docs)
text_chunks = get_text_chunks(raw_text)
get_vector_store(text_chunks)
st.success("Processing complete.")
except Exception as e:
st.error(f"An error occurred: {e}")
if __name__ == "__main__":
main()
To lunch the streamlit app, we have to save the entire code in .py file (chat_pdf. py). After that, we can use the following command with path of the file in command prompt like this,
Command: streamlit run chat_pdf.py

After lunching the python file in command prompt, we will get the web page in the browser.
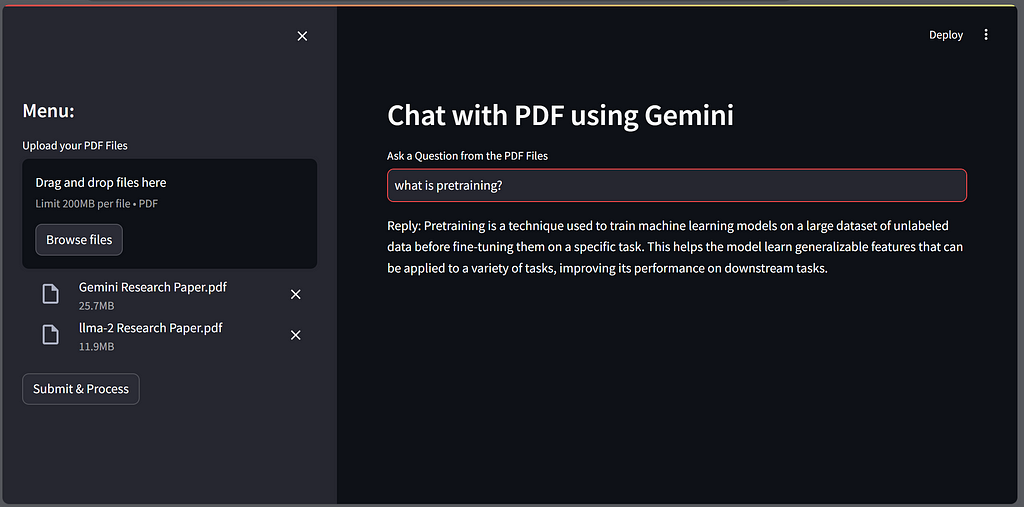
Thank you for Reading!
To learn more:
Google Gemini: https://ai.google.dev/
Vasukumar P
https://medium.com/python-in-pla
Chat with your PDF files by using the Gemini Pro model was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Vasukumar Palanisamy
Vasukumar Palanisamy | Sciencx (2024-06-30T18:08:41+00:00) Chat with your PDF files by using the Gemini Pro model. Retrieved from https://www.scien.cx/2024/06/30/chat-with-your-pdf-files-by-using-the-gemini-pro-model/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.