
This content originally appeared on HackerNoon and was authored by UserStory
:::info Authors:
(1) Wen Wang, Zhejiang University, Hangzhou, China and Equal Contribution (wwenxyz@zju.edu.cn);
(2) Canyu Zhao, Zhejiang University, Hangzhou, China and Equal Contribution (volcverse@zju.edu.cn);
(3) Hao Chen, Zhejiang University, Hangzhou, China (haochen.cad@zju.edu.cn);
(4) Zhekai Chen, Zhejiang University, Hangzhou, China (chenzhekai@zju.edu.cn);
(5) Kecheng Zheng, Zhejiang University, Hangzhou, China (zkechengzk@gmail.com);
(6) Chunhua Shen, Zhejiang University, Hangzhou, China (chunhuashen@zju.edu.cn).
:::
Table of Links
3 OUR METHOD
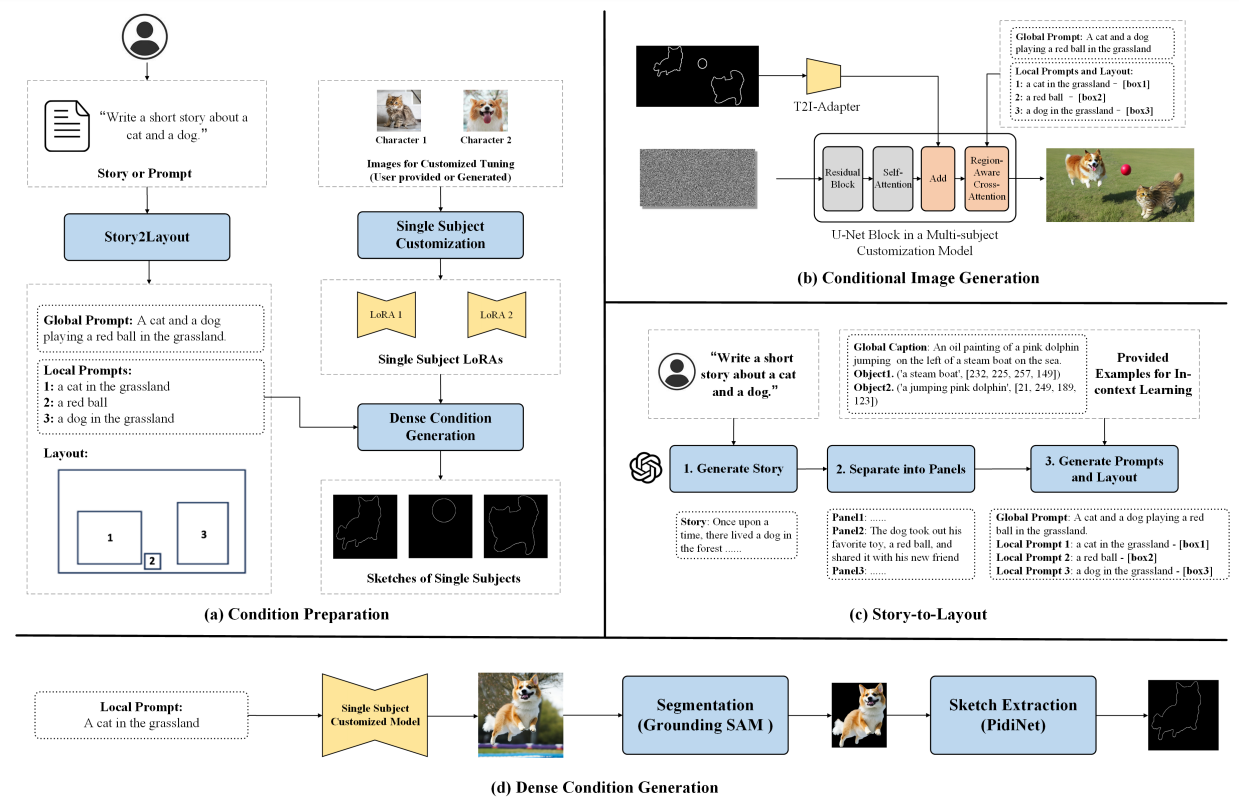
The goal of our method is to generate diverse storytelling images of high quality and with minimal human effort. Considering the complexity of scenes in storytelling images, our general idea is to combine the comprehension and planning capabilities of LLMs [et al 2023; OpenAI 2023] and the generation ability of the large-scale text-to-image models [Rombach et al. 2022]. The pipeline is shown in Fig. 2, which can be divided into a condition preparation stage in (a) and a conditional image generation stage in (b). Specifically, we first utilize LLMs to convert the textual descriptions of stories into layouts of the storytelling images, as detailed in Sec. 3.1. To improve the quality of generated story images, we propose a simple yet effective method to transform sparse bounding boxes into dense control signals like sketches or keypoints, without introducing manual labor (detailed in Sec. 3.2). Subsequently, we generate story images with a reasonable scene arrangement based on the layout, as detailed in Sec. 3.3. Finally, we propose a method to eliminate the requirement for users to collect training data for each character, enabling the generation of identity-consistent story images from only texts (detailed in Sec. 3.4). Since our approach only fine-tunes the pre-trained text-to-image image diffusion model on a few images, we can easily leverage existing models on civiati[1] for storytelling in arbitrary characters, scenes, and even styles.
3.1 Story to Layout Generation

\ Layout Generation. After dividing the story into panel descriptions, we leverage LLMs to extract the scene layout from each panel description, as shown in the following equation:
\

\
\

3.2 Dense Condition Generation
Motivation. Although using sparse bounding boxes as a control signal can improve the generation of subjects and obtain more reasonable scene layouts, we find that it cannot consistently produce high-quality generation results. There are cases where the images do not exactly match the scene layout or the generated images are of low quality, as detailed in the experiments in Sec. 4.4.
\ We believe that this is mainly due to the limited information provided by the bounding boxes. The model faces difficulties in generating a large amount of content all at once, with limited guidance. For this reason, we propose to improve the final story image generation by introducing dense sketch or keypoint guidances. To this end, we devise a dense condition generation module based on the layout generated in the previous section, as shown in Fig. 2(d).
\

\ Note that the process of composing dense conditions is fully automatic and does not require any manual interaction.
3.3 Controllable Storytelling Image Generation
Large-scale pre-trained text-to-image models, such as Stable Diffusion [Rombach et al. 2022], are capable of generating images from text. However, limited by the language comprehension ability of the text encoder in the model, and the incorrect association between text and image regions in the generation process, the directly generated images often suffer from a series of problems such as object missing, attribution confusion, etc [Chefer et al. 2023]. To tackle this, we introduce additional control signals to improve the quality of image generation.
\

3.4 Eliminating Character-wise Data Collection

\
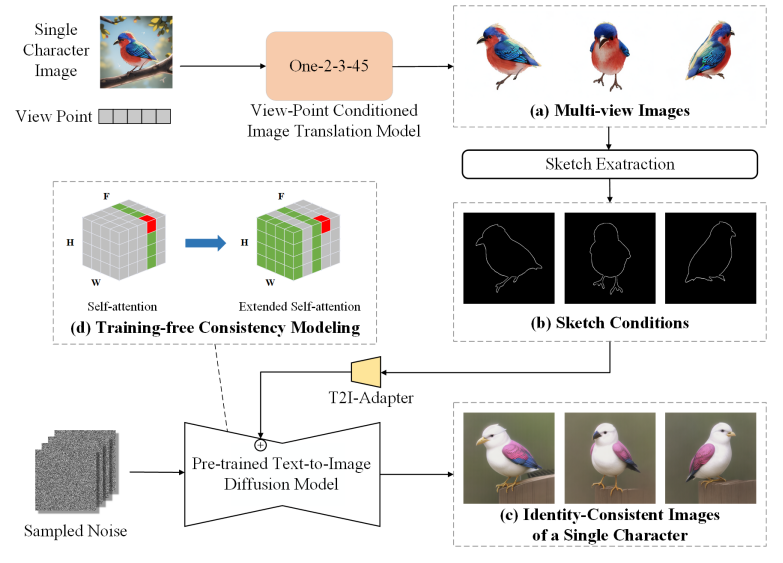
\ Identity Consistency. We propose a training-free consistency modeling method to meet the requirement of identity consistency, as shown in Fig. 3 (d). Specifically, we treat multiple images of a single character as different frames in a video and generate them simultaneously using a pre-trained diffusion model. In this process, the self-attention in the generative model is expanded to other “video frames" [Wang et al. 2023; Wu et al. 2022] to strengthen the dependencies among images, thus obtaining identity-consistent generation results. Concretely, in self-attention, we let the latent features in each frame attend to the features in the first and previous frames to build the dependency. The process can be represented as:
\
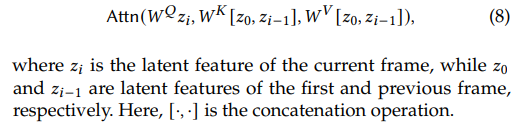
\

\ Subsequently, we extract sketches for non-human characters and keypoints for human characters from these images. Finally, we use T2I-Adapter to inject the control guidance into the latent feature of corresponding frames in the generation process.
\ In addition, in order to further ensure the quality of the generated data, we use CLIP score to filter the generated data, and select the images that are consistent with the text descriptions as the training data for customized generation.
\ Discussion. In this section, we combine the proposed training-free identity-consistency modeling method with the viewpoint conditioned image translation model to achieve both identity consistency and diversity in character generation. A simpler approach is to directly use the multi-view images from the view-point conditioned image translation model as training data for customization. However, we found that the directly generated results often suffer from distortions or large differences in the color and texture of the images from different viewpoints (see Sec. 4.4 for details). For this reason, we need to leverage the above consistency modeling approach to obtain both texture- and structure-consistent images for each character.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
[1] https://civitai.com
This content originally appeared on HackerNoon and was authored by UserStory
UserStory | Sciencx (2024-07-17T11:30:19+00:00) AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort: Our Method. Retrieved from https://www.scien.cx/2024/07/17/autostory-generating-diverse-storytelling-images-with-minimal-human-effort-our-method/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.