
This content originally appeared on HackerNoon and was authored by Vladimir Filipchenko
Because life is too short to redraw diagrams
I recently joined a new company as a Software Engineer. As it always happens, I had to start from scratch. Things like: Where’s the code for an app live? How does it get deployed? Where do the configs come from? Thankfully, my colleagues did a fantastic job of making everything ‘infrastructure as code.’ So I caught myself thinking: If everything is in the code, why isn't there a tool to connect all the dots?
\ This tool would review the codebase and build an application architecture diagram, highlighting key aspects. A new engineer could look at the diagram and say, “Ah, okay, this is how it works."
\
First things first
No matter how hard I searched, I couldn’t find anything like that. The closest matches I found were services that draw an infrastructure diagram. I put some of them into this review so you can take a closer look. Eventually, I gave up googling and decided to try my hands at developing some new cool stuff.
\ First, I built a sample Java app with Gradle, Docker, and Terraform. GitHub actions pipeline deploys the app on Amazon Elastic Container Service. This repo will be a source for the tool I will build (code is here).
\ Second, I drew a very high-level diagram of what I wanted to see as a result:
\
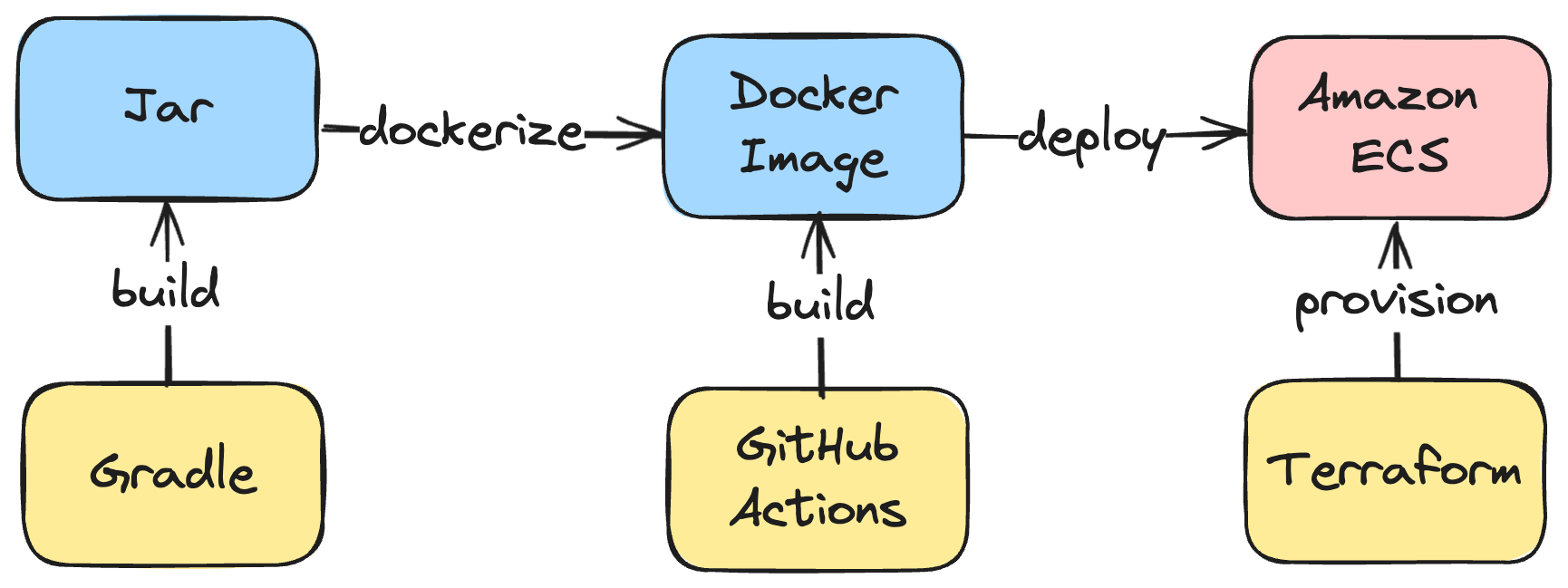
\ I decided there would be two types of resources:
Relic
I found the term artifact too overloaded, so I chose ==Relic==. So what is a Relic? It’s 90% of anything you want to see. Including, but not limited to:
- Artifacts (blue boxes on the scheme, i.e., Jars, Docker images),
- Configs Terraform resources (pink boxes on the scheme, i.e., EC2 instances, ECS, SQS queues),
- Kubernetes resources,
- and many-many more
\ Every Relic has a name (e.g., my-shiny-app), optional type (e.g., Jar), and a set of key → value pairs (e.g., path → /build/libs/my-shiny-app.jar) that fully describes Relic. They are called ==Definitions==. The more Definitions Relic has - the better.
Source
The second type is a ==Source==. Sources define, build, or provision Relics (e.g., yellow boxes above). A Source describes a Relic in some place and gives a sense of where it comes from. While Sources are the components from which we get the most information, they usually have secondary meanings on the diagram. You probably don’t need a lot of arrows going from Terraform or Gradle to every other Relic.
\ Relic and Source have a many-to-many relationship.
\
Divide and conquer
Covering every piece of code is impossible. Modern apps could have many frameworks, tools, or cloud components. AWS alone has around 950 resources and data sources for Terraform! The tool has to be easily extendable and decoupled by design so that other people or companies can contribute.
\ While I am a massive fan of incredibly pluggable Terraform providers' architecture, I decided to build the same, albeit simplified:
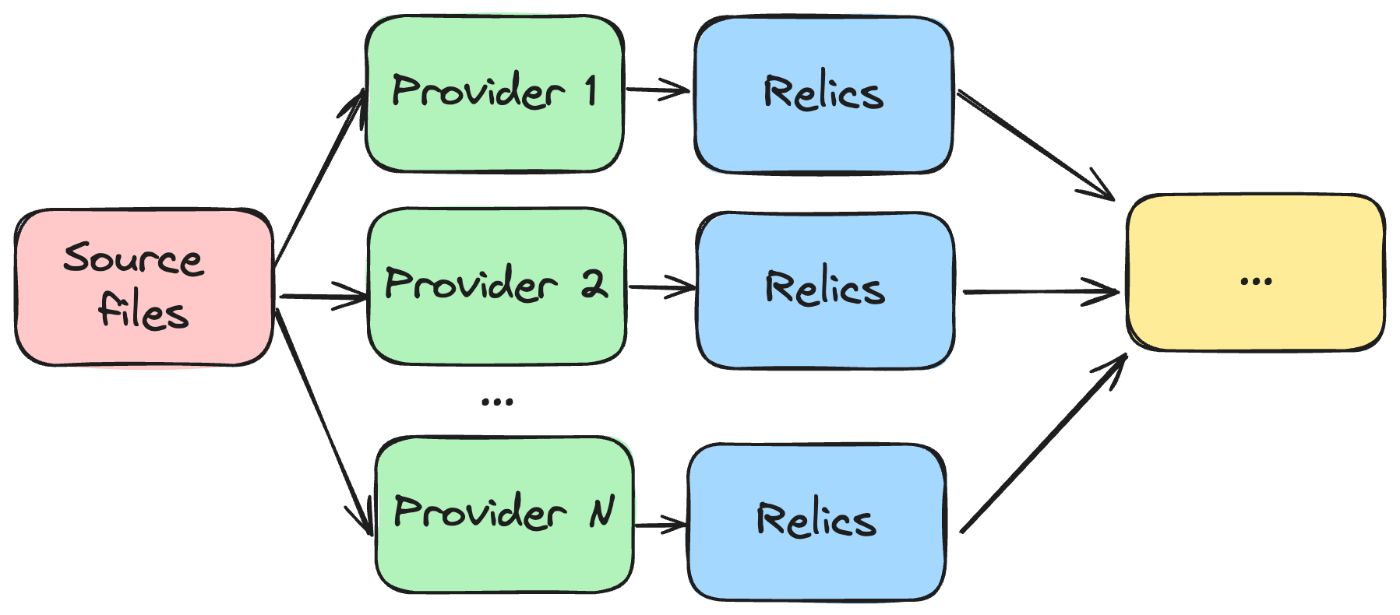
\ The ==Provider== has one clear responsibility: building Relics based on the requested source files. For example, GradleProvider reads *.gradle files and returns Jar, War, or Gz Relics. Each provider builds Relics of the types they are aware of. Providers don’t care about interactions between Relics. They build Relics declaratively, wholly isolated from each other.
\ With that approach, it’s easy to go as deep as you want. A good example is GitHub Actions. A typical workflow YAML file consists of dozens of steps using loosely coupled components and services. A workflow could build a JAR, then a Docker image, and deploy it to the environment. Every single step in the workflow could be covered by its provider. So, developers of, let’s say, Docker Actions create a Provider related only to the steps they care about.
\ This approach allows any number of people to work in parallel, adding more logic to the tool. End users can also quickly implement their Providers (in the case of some proprietary tech). See more under Customization below.
\
To merge or not to merge
Let’s look into the next trap before going into the juiciest part. Two Providers, each of which creates one Relic. That’s fine. But what if two of these Relics are just representations of the same component defined in two places? Here is an example.
\ AmazonECSProvider parses task definition JSON and produces a Relic with the type AmazonECSTask. The GitHub action workflow also has an ECS-related step, so another provider creates an AmazonECSTaskDeployment Relic. Now, we have duplicates because both providers know nothing about each other. Moreover, it’s incorrect for any of them to assume that another has already created a Relic. Then what?
\
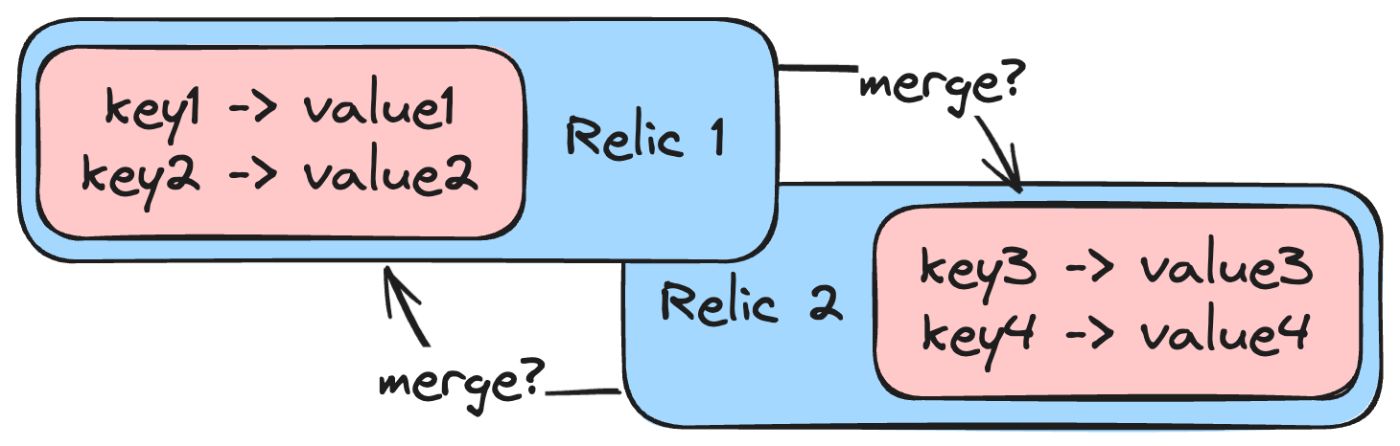
\ We can’t drop either of the duplicates because of the Definitions (attributes) each of them has. The only way is to merge them. By default, the next logic defines merging decision:
\
relic1.name() == relic2.name() && relic1.source() != relic2.source()
\ We merge two Relics if their names are equal, but they are defined in different Sources (like in our example, JSON in the repo and task definition reference is in GithHub Actions).
\ When we merge, we:
- Chose single name
- Merge all Definitions (key → value pairs)
- Create a composite Source referring to both original Sources
\
Draw a line
I intentionally omitted one crucial aspect of a Relic. It may have a ==Matcher== — and it’s better to have it! The Matcher is a boolean function that takes an argument and tests it. Matchers are crucial pieces of a linking process. If a Relic matches any definition of another’s Relic, they will be linked together.
\ Remember when I said that Providers have no clue about Relics created by other Providers? That’s still true. However, a Provider defines a Matcher for a Relic. In other words, it represents one side of an arrow between two boxes on the resulting diagram.
\
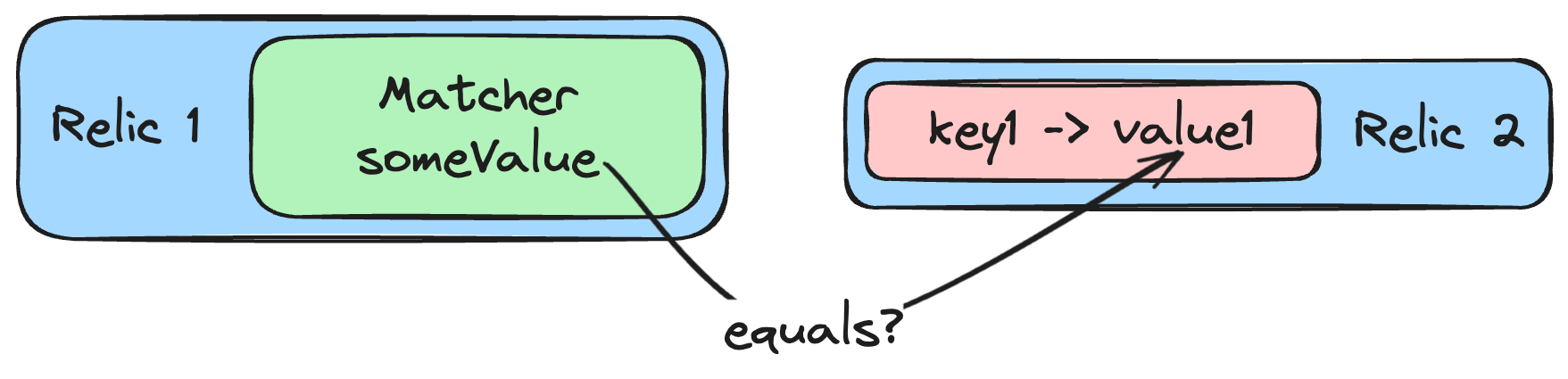
\ Example. Dockerfile has an ENTRYPOINT instruction.
\
ENTRYPOINT java -jar /app/arch-diagram-sample.jar
\
With some certainty, we can say that Docker containerizes whatever is specified under the ENTRYPOINT. So, the Dockerfile Relic has a simple Matcher function: entrypointInstruction.contains(anotherRelicsDefinition). Most probably, some Jar Relics with arch-diagram-sample.jar in the Definitions will match it. If yes, an arrow between Dockerfile and Jar Relics appears.
\ With Matcher defined, the linking process looks pretty straightforward. The linking service iterates over all Relics and calls their Matcher’s functions. Does Relic A match any of the Relic’s B definitions? Yes? Add an edge between those Relics in the resulting graph. The edge could also be named.
\
Visualization
The last step is to visualize our final graph of the prior stage. In addition to the obvious PNG, the tool supports additional formats, such as Mermaid, Plant UML, and DOT. These text formats might look less attractive, but the huge advantage is that you can embed those texts into almost any wiki page (GitHub, Confluence, and many more).
\ Here is how the final diagram of the sample repo looks:
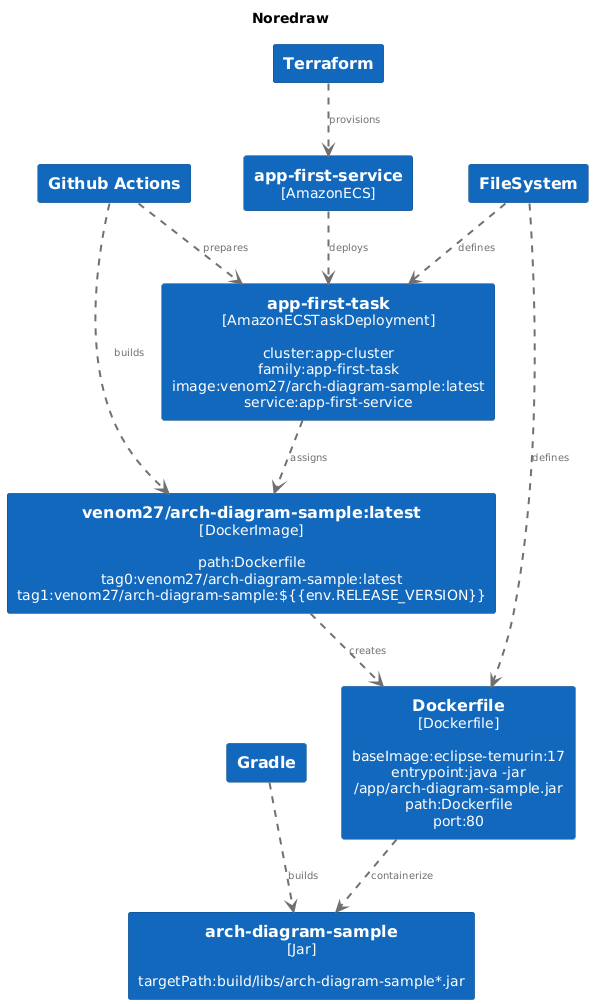
\
Customization
The ability to plug in custom components or tweak existing logic is essential, especially when a tool is in its initial phase. Relics and Sources are flexible enough by default; you can put whatever you want into them. Every other component is customizable. Existing Providers don’t cover the resources you need? Implement your own with ease. Not satisfied with the merging or linking logic described above? No problem; add your own LinkStrategy or MergeStrategy. Pack everything into a JAR file and add it on startup. Read more here.
\
Outro
Generating a diagram based on source code will likely gain traction. And ==NoReDraw== tool in particular (yes, this is the name of the tool I was talking about). Contributors are welcome!
\ The most remarkable benefit (which comes from the name) is that there is no need to redraw a diagram when components change. The lack of engineering attention is why documentation in general (and diagrams in particular) gets outdated. With tools like ==NoReDraw==, it shouldn’t be a problem anymore as it is easily pluggable to any PR/CI pipeline. Remember, life is too short to redraw diagrams 😉
This content originally appeared on HackerNoon and was authored by Vladimir Filipchenko
Vladimir Filipchenko | Sciencx (2024-07-30T08:00:14+00:00) Automating App Architecture Diagrams: How I Built a Tool to Map Codebases from the Source. Retrieved from https://www.scien.cx/2024/07/30/automating-app-architecture-diagrams-how-i-built-a-tool-to-map-codebases-from-the-source/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.