
This content originally appeared on HackerNoon and was authored by Tech Media Bias [Research Publication]
Table of Links
3 End-to-End Adaptive Local Learning
3.1 Loss-Driven Mixture-of-Experts
3.2 Synchronized Learning via Adaptive Weight
4 Debiasing Experiments and 4.1 Experimental Setup
4.3 Ablation Study
4.4 Effect of the Adaptive Weight Module and 4.5 Hyper-parameter Study
6 Conclusion, Acknowledgements, and References
3.1 Loss-Driven Mixture-of-Experts
Mixture-of-Experts. To address the discrepancy modeling problem, prior works propose the local learning method [12,39] to provide a customized local model trained by a small collection of local data for each user. However, how to curate such a local dataset and how to build a local model are completely hand-crafted in these algorithms, which significantly limits performance. To overcome this weakness, we adopt a Mixture-of-Experts (MoE) [14] structure as the backbone of our proposed framework to implement end-to-end local learning.
\

\ Adaptive Loss-Driven Gate. However, the regular gate model, a free-to-learn feed-forward neural network (i.e., a multilayer perception) within a standard MoE, is also susceptible to various biases, including mainstream bias. The gate model is trained by data with more mainstream users and thus focuses more on how to assign gate values to improve utility for mainstream users while overlooking niche users. This results in an inability of the regular gate model to reasonably assign values to different users, especially niche users. Therefore, such a free-to-learn gate model cannot address the discrepancy modeling problem. A more precise and unbiased gate mechanism is needed.
\ A key principle of the gate model is that when we have a set of expert models, the gate model should assign high values for expert models that are effective for the target user, and low values for expert models less effective for the target user. In this regard, the loss function serves as a high-quality indicator. Specifically, a high loss value in an expert model for a target user means that this expert model is not helpful for delivering prediction, and thus, it should not contribute to the aggregation of the final customized local model, receiving a small gate value. Conversely, a low loss indicates an effective expert model deserving a higher gate value. Based on this intuition, we propose the adaptive loss-driven gate module:
\
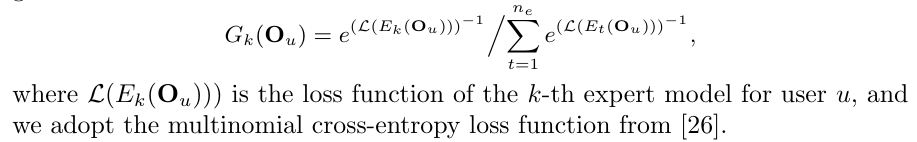
\ This mechanism complies with the principle of allocating high gate values to more effective expert models and low values to irrelevant expert models. In practice, we can use the loss function calculated on training data or independent validation data for the proposed adaptive loss-driven gate mechanism. Due to that loss on previously unseen validation data is a more precise signal of model performance, in this work, we adopt the loss function on validation data to calculate gate values. By this adaptive loss-driven gate mechanism, we can automatically and adaptively assign gate values to expert models, based on which we generate effective customized models.
\
:::info Authors:
(1) Jinhao Pan [0009 −0006 −1574 −6376], Texas A&M University, College Station, TX, USA;
(2) Ziwei Zhu [0000 −0002 −3990 −4774], George Mason University, Fairfax, VA, USA;
(3) Jianling Wang [0000 −0001 −9916 −0976], Texas A&M University, College Station, TX, USA;
(4) Allen Lin [0000 −0003 −0980 −4323], Texas A&M University, College Station, TX, USA;
(5) James Caverlee [0000 −0001 −8350 −8528]. Texas A&M University, College Station, TX, USA.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Tech Media Bias [Research Publication]
Tech Media Bias [Research Publication] | Sciencx (2024-08-21T14:00:20+00:00) Countering Mainstream Bias via End-to-End Adaptive Local Learning: Loss-Driven Mixture-of-Experts. Retrieved from https://www.scien.cx/2024/08/21/countering-mainstream-bias-via-end-to-end-adaptive-local-learning-loss-driven-mixture-of-experts/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.