
This content originally appeared on HackerNoon and was authored by William Guo
\
Introduction
This article primarily summarizes the architecture and code flow of DataX and SeaTunnel, hoping to help readers understand the source code more easily.
DataX
Let’s first get a general understanding of DataX:
GitHub: https://github.com/alibaba/DataX
DataX Architecture
The core architecture of DataX is designed as follows:
\
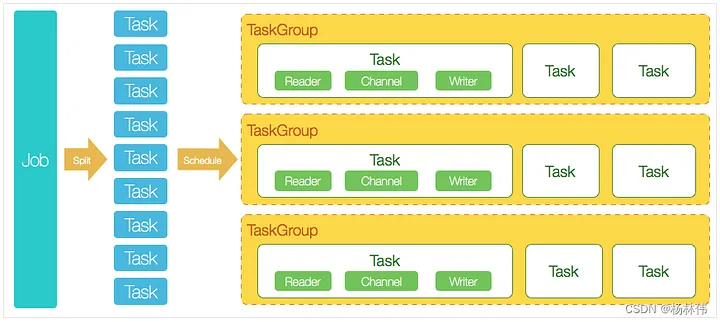
To understand the diagram above, let’s consider a simple example: A user submits a DataX job and configures 20 concurrent tasks to synchronize data from 100 MySQL-sharded tables into ODPS.
\ The DataX scheduling decision process is as follows:
- Step 1: DataXJob splits the 100 tasks based on the sharded tables;
- Step 2: Based on 20 concurrent tasks, DataX calculates that 4 TaskGroups need to be allocated;
- Step 3: The 4 TaskGroups evenly distribute the 100 tasks, each TaskGroup handling 25 tasks at 5 concurrent threads.
\ In the code execution process of DataX, there are several key classes and their responsibilities are as follows (click on the class to view the source code):
\ ClassResponsibilityJobContainerTask containerReaderReader plugin interfaceWriterWriter plugin interfaceJobAssignUtilTask assignment utility classAbstractSchedulerTask scheduling abstract classTaskGroupContainerTask group container
Issues With DataX
First, let’s summarize the advantages of DataX, which include the following:
- Reliable data quality monitoring: such as monitoring traffic, data volume during runtime, and detecting dirty data;
- Rich data transformation features: allowing data to be easily anonymized, completed, filtered, etc., during transmission;
- Precise speed control: enabling control of job speed to achieve the best synchronization speed within the database’s capacity;
\ However, the open-source version of DataX has some serious shortcomings, such as:
- It does not support clustering and only supports single-machine multi-threading mode to complete synchronization tasks
- It does not support real-time processing, e.g., real-time data sources like Kafka and components in the big data ecosystem like Flink.
\ At this point, the emergence of Apache SeaTunnel seems to fill the gaps left by DataX.
Apache SeaTunnel
Let’s get a general understanding of SeaTunnel on its GitHub repository: https://github.com/apache/seatunnel
\ Apache SeaTunnel defines itself as the next-generation high-performance, distributed, massive data integration framework.
\ Okay, let’s continue to look at its relevant functional features.
Architecture of SeaTunnel
This is a brief product design architecture diagram from the official Apache SeaTunnel website:
\
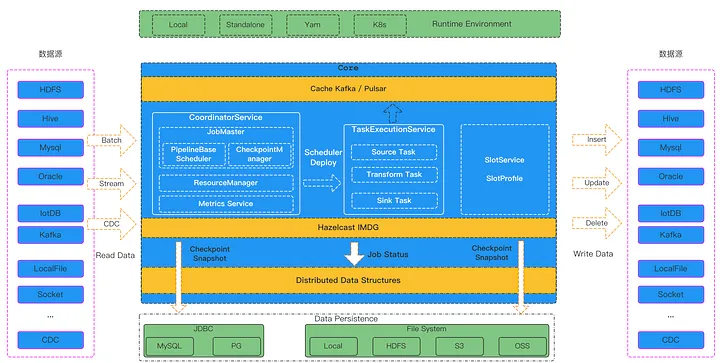
I believe that the self-developed SeaTunnel Engine is the core of the entire SeaTunnel, consisting of three main services (click on the class name to view the corresponding source code):
\ ClassResponsibilityCoordinatorServiceMaster service, responsible for DAG generation, Checkpoint process control, resource management, and job metric statistics and aggregationTaskExecutionServiceWorker service, the actual runtime environment for each task in the jobSlotServiceRuns on every node in the cluster, mainly responsible for resource partitioning, allocation, and recovery on the node
SeaTunnel Code Execution Flow
Regarding the architecture or code execution flow of SeaTunnel, the official website does not seem to provide a corresponding flow design diagram.
\ To better understand the process, I draw a diagram to show the SeaTunnel code execution flow:
\
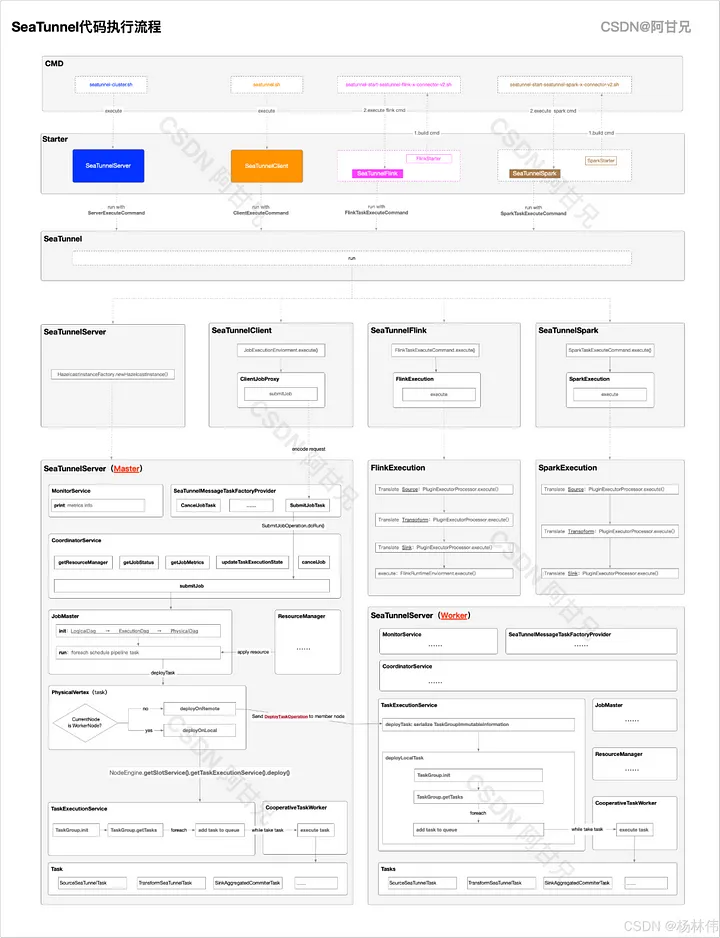
At the CMD command layer (entry point), the following commands are primarily divided into:
- seatunnel-cluster.sh: Mainly used to start the SeaTunnel cluster;
- seatunnel.sh: SeaTunnel client, mainly used to submit jobs to the SeaTunnel cluster or stop running jobs in the cluster;
- seatunnel-start-seatunnel-flink-x-connector-v2.sh: Mainly used to submit jobs to the Flink cluster (Note that the execution script uses the
evalcommand to execute the flink script command printed from the FlinkStarter console); - seatunnel-start-seatunnel-spark-x-connector-v2.sh: Mainly used to submit jobs to the Spark cluster (Note that the execution script uses the
evalcommand to execute the spark script command printed from the SparkStarter console).
\ The execution engine supported by SeaTunnel including:
EngineCore ClassDescriptionSeaTunnel (Zeta) RecommendedSeaTunnelServerDivided into Master and Worker, the Master is mainly responsible for job DAG generation, resource management, metrics, etc.
\
The Worker mainly executes specific task nodes, and each Worker determines whether to execute based on whether the SlotProfile’s IP address is the local address (specifically in org.apache.seatunnel.engine.server.dag.physical.PhysicalVertex#deploy)FlinkSeaTunnelFlinkThe PluginExecutorProcessor types are divided into Source, Sink, and Transform, mainly used to translate SeaTunnel's configuration into a configuration recognizable by Flink, and finally use Flink's TableEnvironment to execute ETL tasksSparkSeaTunnelSparkSimilar to the Flink engine's execution logic, the PluginExecutorProcessor types are divided into Source, Sink, Transform, and finally translated and executed ETL tasks
Conclusion
So far, this article has provided an overview comparison between the architecture and code flow of DataX and SeaTunnel.
\ This article only shows my understanding of the two products after reading their source code. There may be limitations or shortcomings, and readers are welcome to leave comments to point them out. Hope this article is useful to you.
This content originally appeared on HackerNoon and was authored by William Guo
William Guo | Sciencx (2024-08-30T00:11:34+00:00) A 10-Minute Deep Dive Into the Core Architecture of Apache SeaTunnel and DataX. Retrieved from https://www.scien.cx/2024/08/30/a-10-minute-deep-dive-into-the-core-architecture-of-apache-seatunnel-and-datax/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.