
This content originally appeared on HackerNoon and was authored by Gabriel Poeta
When it came time to deploy the application I tried AWS, but honestly I was kind of bummed out with the amount of information and services they provide, and I really wanted to see my application out there in the wild. So I came across Vercel. On top of that, I’ve been learning about Docker and wanted to put into practice what I’ve learnt so far, this was the right opportunity.
\ Vercel is well known for their zero config deployment. With just a couple clicks you can have your application deployed. You can also connect your repository and Vercel will instantly build and deploy your project after every commit. It couldn’t get any more convenient than that 😀 . Another reason I’ve chosen Vercel over AWS was their ‘serverless’ function, which I’ve used to render the documentos from my database through an Express API. To be honest, I can’t complain about their service. I’ve never had any issues with my project whatsoever. The thing here is that I wanted to learn more about the backend of my application and I figured that understanding the deployment of it could help me with that. I’ve seen a lot of people choosing AWS over Vercel because of their pricing plan. It doesn’t apply to my case as my application does not have that much traffic and I’m mainly using it for studying purposes. But it is good to mention that Vercel has an “issue” with escalation when it comes to pricing.
\ The Toronto Food Basket application can be splitted in three different parts:
Webscraper for gathering information from a local grocery store
Express API that organizes the information and can perform mathematical operations to do so.
React app that renders the application and all the needed information.
\
For now I’m only deploying the Webscraper to AWS as I still need to learn more about servers and routes to deploy the Express API and the React app. To start with I launched an AWS EC2 instance and set a budget alarm so any time the spending on my instance goes over $0.01 I get a notification - learnt that the hard way after being billed for a DocumentDB instance I had running in my account since December/2023 and had no idea 😂. Amazon provides free tiers with 750 hours of t2.micro (or t3.micro in the Regions in which t2.micro is unavailable), 30Gib of EBS storage, 2 million IOs, 1 GB of snapshots and 100 GB of bandwidth to the internet.
\ While learning how to deploy my dockerized application on AWS I realized that there are at least two different approaches - there might be more:
\
build the docker container locally and send only the container over to AWS.
send everything to AWS and build my container remotely.
\
I’ve chosen the second approach because I wanted to have the experience of working completely remote on my application if I had to. I’m not always on my own computer and having my application on an EC2 instance would be really handy in those situations. Also, I would be forced to work with Vim, which is something that I’ve been wanting to do. Before sending over the files to my EC2 instance I prepared my remote environment by installing Node.js and Docker.
\ In order to send the files over to my EC2 instance I used the Secure Copy Protocol (scp). The command looked something like this:
scp -i ubuntu.pem -r LOCAL_DIRECTORY ubuntu@35.183.21.127:/home/ubuntu/downloads/webscraperdockeraws
\
-i ubuntu.pem: This flag specifies the identity file (private key) to use for public key authentication. In this case,ubuntu.pemis the private key file used to authenticate to the remote server.-r: This flag indicates that the operation should be recursive, meaning it will copy directories and their contents recursively.ubuntu@35.183.21.127:/home/ubuntu/downloads/webscraperdockeraws: This is the destination specification. It includes the username (ubuntu) and the IP address (35.183.21.127) of the remote server, followed by the directory path (/home/ubuntu/downloads) where the files will be copied to.
\ Once all files were transferred to my EC2 instance I was able to then build my docker container. And here the bugs started - yay! The most important library of my Webscraper is Puppeteer, which provides a high-level API to control Chrome/Chromium over the DevTools Protocol. Puppeteer runs in a headless mode, making its execution faster. But when trying to dockerize my application I came across some issues:
\
By default, when Puppeteer is installed it downloads the Chrome for Testing and a chrome-headless-shell binary. The browser is downloaded to the $HOME/.cache/puppeteer folder. The problem is that AWS does not include include a $HOME/.cache into its Ubuntu instance. I found out this issue after some research, and to solve all I had to do was move the /.cache folder to the root directory - this issue is well documented on Puppeteers’s npm portal.
\

\
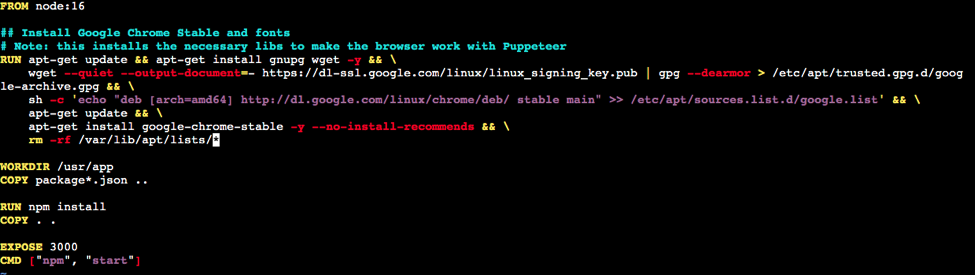
One obvious thing I haven’t realized was that up until now I was running my application in OS like Windows and MacOs.. But now I was dealing with Ubuntu. And because it was an empty instance it didn't any package/app pre-installed, this is why I installed node and docker as soon as I ran the instance for the first time. But I was forgetting a really important application for my Webscraper to work: Google Chrome. Remember what I said about Puppeteer before? Well, I needed to make sure I had the right version of Chromium on my instance . Every major version of Node.js is built over a version of Debian, and that Debian version comes with an old version of Chromium, which sometimes is not compatible with the latest version of Puppeteer. After some research I found out I had to include an instruction in my Dockerfile so the right version of Chromium could be downloaded before Docker installs all the dependencies of my app and runs it. My Docker file looked something like this:
\
\
\
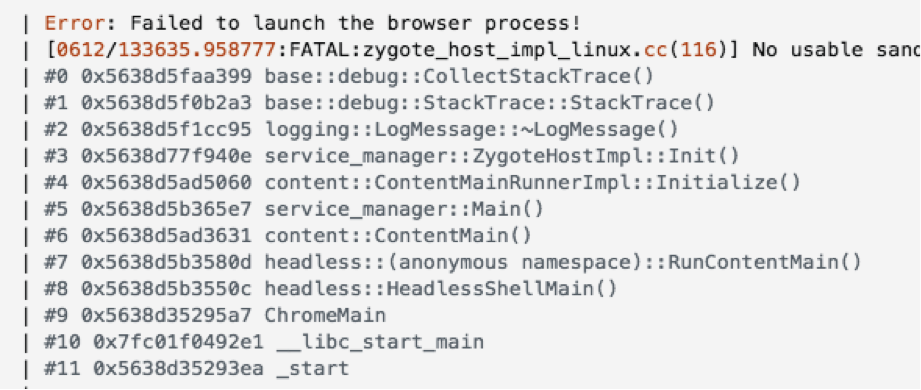
After fixing the previous issue another one came up. Now the error message states: “No usable sandbox”. To fix it all I had to do was change my code and include a –no-sandbox argument on puppeteer.launch() function for every single one of my grocery products.
\

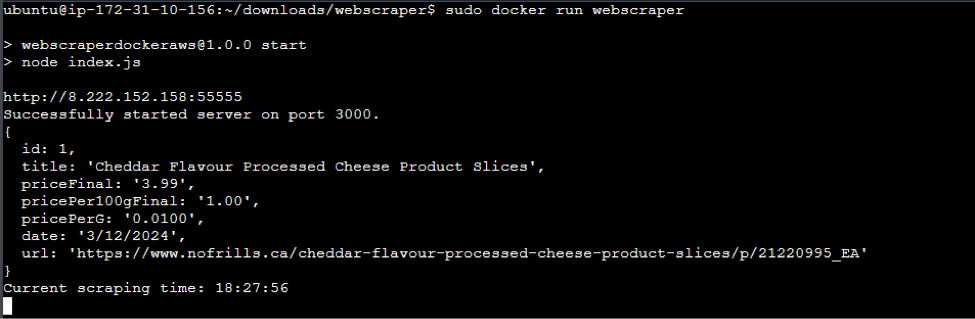
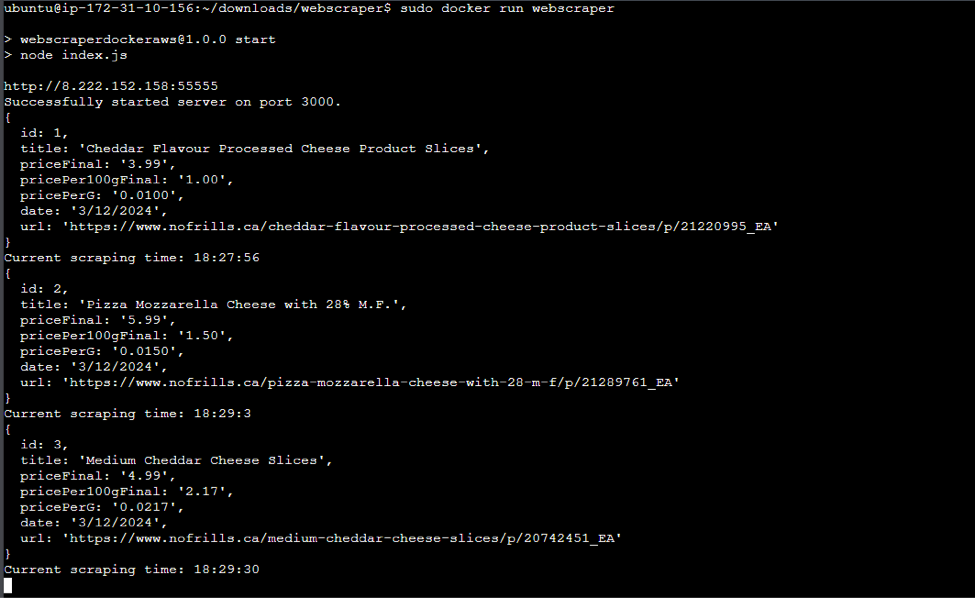
\ Done. Now my Webscraper runs in a container on my AWS EC2 instance. It wont scrape all 65 products though.. After the fifth product the app crashes. I believe it has something to do with the available resources I have on this instance - I was facing the same problem when running the scraper with github actions. Anyway, my goal was to launch an AWS EC2 instance and have my application running remotely, and I did. Lots to come!
\
\
\ \ \
This content originally appeared on HackerNoon and was authored by Gabriel Poeta
Gabriel Poeta | Sciencx (2024-09-05T19:00:25+00:00) Solving the ‘It Works on my Machine’ Problem. Retrieved from https://www.scien.cx/2024/09/05/solving-the-it-works-on-my-machine-problem/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.