
This content originally appeared on DEV Community and was authored by Nick K
Trieve's infrastructure contains both Postgres and a dedicated search engine which is not ideal. It would be great if we could use postgres by itself with pgvector, but it is not a complete solution. Here we explain what pgvector is missing beyond scalability.
If you need horizontal scaling due to vector count (~5+ million) or replication, postgres is not the right solution. However, that's been discussed extensively elsewhere and we don't want to rehash it.
1. Required and Negated Words
Dense vector search is not perfect and will fail on queries like emails where Rob praises the team and does not mention productivity. Vectors created by the embedding models don't properly respect productivity being a term to avoid.
With negated words, the fix is simple, you can change the query to emails where Rob praises the team -productivity. Or, vice versa, you could narrow down your result set by requiring a term like emails where Rob praises the team "productivity".
Postgres does support LIKE queries which would allow you to semi-replicate this behavior without prefix expansion, but it has performance issues because some search terms prevent efficient index usage.
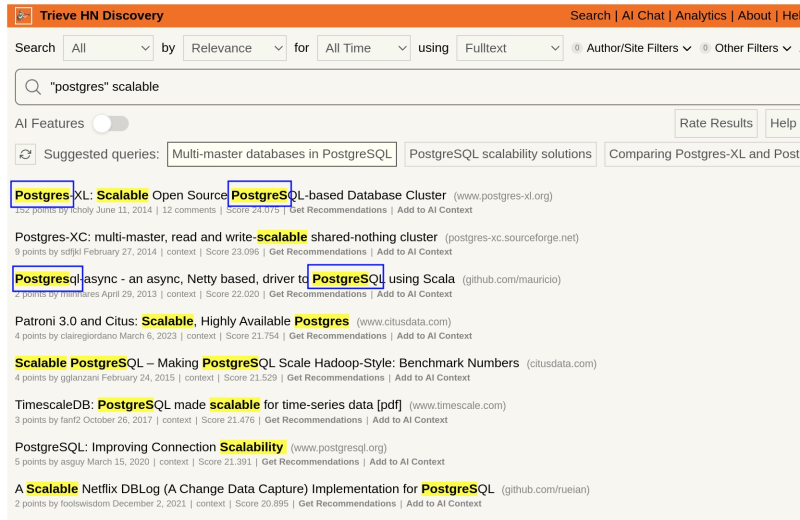
Even if you build business logic and performance tune your postgres instance, it still won't perform as well as a dedicated search solution with native prefix expansion. You don't want a user requiring the term "postgres" to miss every result containing "PostgreSQL". Dedicated search solutions like Trieve handle this in a way that postgres-oriented solutions cannot.
2. Explainability With Highlights
Postgres pgvector does not come up with a way to highlight the keyword snippets being matched on. This creates a huge problem for UX. Trieve and other search-specific solutions have this out of the box.
We can spend our whole lives optimizing search systems and there will still be queries which perform poorly. The good news is that search is not a one-shot problem and users can reformulate their queries to better find what they're looking for.
Someone can look at the search results, see they are not ideal, and come up with mental reasoning for why such that they can self-correct. In the following scenario, they might consider replacing async with parallel as the highlights clearly indicate that async is the problem-phrase what the system is keying in on.

If we replace async with parallel, voila! It works beautifully! It would be very difficult for a user to identify the problem and make that change without highlights.

3. Performant Filters and Order By's
Pgvector is very slow, seconds to 10's of seconds, on filter and order by queries. Its maintainers are working on this as you can see in this currently 83 comment long issue on Github and pgvector.rs has made improvements as you can see here, but it's messy. I strongly believe that you don't want to be fighting through these issues when adding semantic search to your product. It's going to be a long term, hard fought struggle to keep up with pgvector's updates here and continuously tune it.
Trieve and other search solutions, in contrast, are going to be easy. You can try it yourself on our hacker news search engine and see that on large datasets (up to billions of documents), Trieve's handling of segments and scale gaurantees that filters and order by's are 0 cost.
4. Support for sparse vectors, BM25, and other inverse document frequency search modes
PGVector will only allow you to bulid semantic search and not fulltext which can create instances of users trained on keyword search hitting your new fancy system, trying hit, seeing bad results, and churning because they feel like the "newfangled AI" is overhyped and not ready.
Professionals today have decades of experience built up using keyword search and semantic search is a different pattern. It's amazing and unlocks new possibilities, but needs to be introduced to our products without breaking users' assumptions.
Users will most naturally search for something like gatekeeping in tech when looking for information on that topic. However, that query is much better suited for SPLADE fulltext search than dense vector semantic. Exploring the impact of gatekeeping on diversity the tech industry is a much better semantic search query.
Defaulting to fulltext and adding semantic as an option gives your users the time to figure out how best to use the new dense vector semantic search workflow and prevents them from churning due to bad first impressions. Trieve comes with both the features and technical expertise to help you achieve this.
PGVector is not always a bad choice
Our goal with this post is to inform readers about the potential downside and pitfalls of PGVector. We are not saying that it's always the wrong choice. Simplicity is powerful and may outweigh the above missing features.
We are always happy to chat search outside outside of Trieve as a solution. If you have further questions, please book a meeting with me here, join us on discord and chat async, or send us an email at humans@trieve.ai.
This content originally appeared on DEV Community and was authored by Nick K
Nick K | Sciencx (2024-09-13T22:52:39+00:00) PGVector’s Missing Features. Retrieved from https://www.scien.cx/2024/09/13/pgvectors-missing-features/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.