
This content originally appeared on HackerNoon and was authored by Backpropagation
:::info Authors:
(1) Luyang Zhu, University of Washington and Google Research, and work done while the author was an intern at Google;
(2) Dawei Yang, Google Research;
(3) Tyler Zhu, Google Research;
(4) Fitsum Reda, Google Research;
(5) William Chan, Google Research;
(6) Chitwan Saharia, Google Research;
(7) Mohammad Norouzi, Google Research;
(8) Ira Kemelmacher-Shlizerman, University of Washington and Google Research.
:::
Table of Links
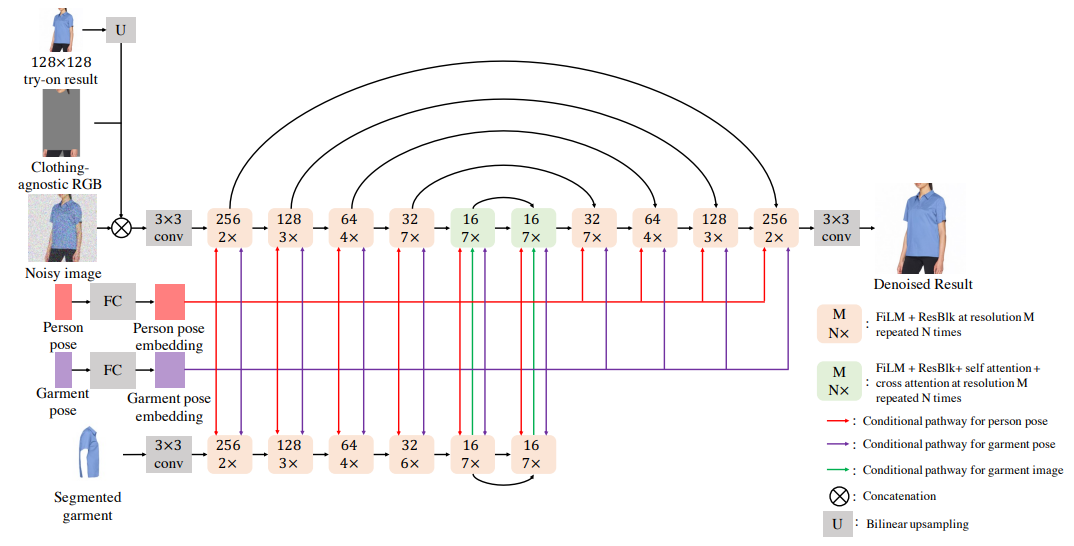
3.1. Cascaded Diffusion Models for Try-On
5. Summary and Future Work and References
\ Appendix
B. Additional Results
In Fig. 9 and 10, we provide qualitative comparison to state-of-the-art methods on challenging cases. We select input pairs from our 6K testing dataset with heavy occlusions and extreme body pose and shape differences. We can see that our method can generate more realistic results compared to baselines. In Fig. 11 and 12, we provide qualitative comparison to state-of-the-art methods on simple cases. We select input pairs from our 6K test dataset with minimum garment warp and simple texture pattern. Baseline methods perform better for simple cases than for challenging cases. However, our method is still better at garment detail preservation and blending (of person and garment). In Fig. 13, we provide more qualitative results on the VITON-HD unpaired testing dataset.
\ For fair comparison, we run a new user study to compare SDAFN [2] vs our method at SDAFN’s 256 × 256 resolution. To generate a 256 × 256 image with our method, we only run inference on the first two stages of our cascaded diffusion models and ignore the 256×256→1024×1024 SR diffusion. Table 3 shows results consistent with the user study reported in the paper. We also compare to HRVITON [25] using their released checkpoints. Note that original HR-VTION is trained on frontal garment images, so we select input garments satisfying this constraint to avoid unfair comparison. Fig. 16 shows that our method is still better than HR-VITON under its optimal cases using its released checkpoints.
\ Table 4 reports quantitative results for ablation studies. Fig. 14 visualizes more examples for the ablation study of combining warp and blend versus sequencing the tasks. Fig. 15 provides more qualitative comparisons between concatenation and cross attention for implicit warping.
\ g. We further investigate the effect of the training dataset size. We retrained our method from scratch on 10K and 100K random pairs from our 4M set and report quantitative results (FID and KID) on two different test sets in Table 5. Fig. 17 also shows visual results for our models trained on different dataset sizes.
\ In Fig. 6 of the main paper, we provide failure cases due to erroneous garment segmentation and garment leaks in the clothing-agnostic RGB image. In Fig. 18, we provide more failure cases of our method. The main problem lies in the clothing-agnostic RGB image. Specifically, it removes part of the identity information from the target person, e.g., tattoos (row one), muscle structure (row two), fine hair on the skin (row two) and accessories (row three). To better visualize the difference in person identity, Fig. 19 provides try-on results on paired unseen test samples, where groundtruth is available.
\ Fig. 20 shows try-on results for a challenging case, where input person wearing garment with no folds, and input garment with folds. We can see that our method can generate realistic folds according to the person pose instead of copying folds from the garment input. Fig. 21 and 22 show TryOnDiffusion results on variety of people and garments for both men and women.
\ Finally, Fig. 23 to 28 provide zoom-in visualization for
\
\
![Table 3. User study comparing SDAFN [2] to our method at 256×256 resolution.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-up930rc.png)
\
![Table 4. Quantitative comparison for ablation studies. We compute FID and KID on our 6K test set and VITON-HD’s unpaired test set. The KID is scaled by 1000 following [22].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-5ua302w.png)
\ Fig. 1 of the main paper, demonstrating high quality results of our method.
\
![Table 5. Quantitative results for the effects of the training set size. We compute FID and KID on our 6K test set and VITON-HD’s unpaired test set. The KID is scaled by 1000 following [22].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-3ob30n8.png)
\
![Figure 9. Comparison with TryOnGAN [26], SDAFN [2] and HR-VITON [25] on challenging cases for women. Compared to baselines, TryOnDiffusion can preserve garment details for heavy occlusions as well as extreme body pose and shape differences. Please zoom in to see details.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-iqc307u.png)
\
![Figure 10. Comparison with TryOnGAN [26], SDAFN [2] and HR-VITON [25] on challenging cases for men. Compared to baselines, TryOnDiffusion can preserve garment details for heavy occlusions as well as extreme body pose and shape differences. Please zoom in to see details.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-y0d30u4.png)
\
![Figure 11. Comparison with TryOnGAN [26], SDAFN [2] and HR-VITON [25] on simple cases for women. We select input pairs with minimum garment warp and simple texture pattern. Baseline methods perform better for simple cases than for challenging cases. However, our method is still better at garment detail preservation and blending (of person and garment). Please zoom in to see details.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-cqe308p.png)
\
![Figure 12. Comparison with TryOnGAN [26], SDAFN [2] and HR-VITON [25] on simple cases for men. We select input pairs with minimum garment warp and simple texture pattern. Baseline methods perform better for simple cases than for challenging cases. However, our method is still better at garment detail preservation and blending (of person and garment). Please zoom in to see details.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-5jf30jm.png)
\
![Figure 13. Comparison with state-of-the-art methods on VITON-HD unpaired testing dataset [6]. All methods were trained on the same 4M dataset and tested on VITON-HD. Please zoom in to see details](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-0kg30gy.png)
\

\

\

\

\

\

\

\

\

\

\

\

\

\

\

\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Backpropagation
Backpropagation | Sciencx (2024-10-06T20:04:41+00:00) Comparative Analysis of TryOnDiffusion with Other State-of-the-Art Methods. Retrieved from https://www.scien.cx/2024/10/06/comparative-analysis-of-tryondiffusion-with-other-state-of-the-art-methods/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.