
This content originally appeared on HackerNoon and was authored by Auto Encoder: How to Ignore the Signal Noise
:::info Authors:
(1) Liang Wang, Microsoft Corporation, and Correspondence to (wangliang@microsoft.com);
(2) Nan Yang, Microsoft Corporation, and correspondence to (nanya@microsoft.com);
(3) Xiaolong Huang, Microsoft Corporation;
(4) Linjun Yang, Microsoft Corporation;
(5) Rangan Majumder, Microsoft Corporation;
(6) Furu Wei, Microsoft Corporation and Correspondence to (fuwei@microsoft.com).
:::
Table of Links
3 Method
4 Experiments
4.1 Statistics of the Synthetic Data
4.2 Model Fine-tuning and Evaluation
5 Analysis
5.1 Is Contrastive Pre-training Necessary?
5.2 Extending to Long Text Embeddings and 5.3 Analysis of Training Hyperparameters
B Test Set Contamination Analysis
C Prompts for Synthetic Data Generation
D Instructions for Training and Evaluation
4 Experiments
4.1 Statistics of the Synthetic Data
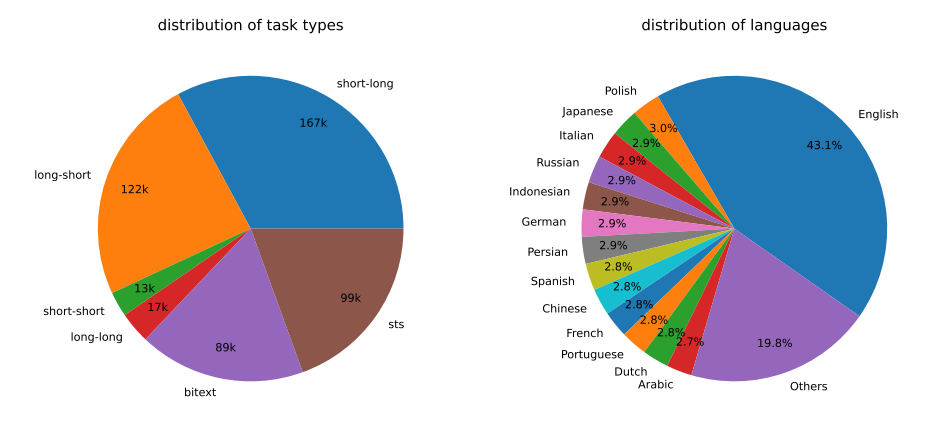
\ Figure 2 presents the statistics of our generated synthetic data. We manage to generate 500k examples with 150k unique instructions using Azure OpenAI Service [2], among which 25% are generated by GPT-35-Turbo and others are generated by GPT-4. The total token consumption is about 180M. The predominant language is English, with coverage extending to a total of 93 languages. For the bottom 75 low-resource languages, there are about 1k examples per language on average.
\ In terms of data quality, we find that a portion of GPT-35-Turbo outputs do not strictly follow the guidelines specified in the prompt templates. Nevertheless, the overall quality remains acceptable, and preliminary experiments have demonstrated the benefits of incorporating this data subset.
\
:::info This paper is available on arxiv under CC0 1.0 DEED license.
:::
[2] https://oai.azure.com/
This content originally appeared on HackerNoon and was authored by Auto Encoder: How to Ignore the Signal Noise
Auto Encoder: How to Ignore the Signal Noise | Sciencx (2024-10-09T15:00:20+00:00) Improving Text Embeddings with Large Language Models: Statistics of the Synthetic Data. Retrieved from https://www.scien.cx/2024/10/09/improving-text-embeddings-withlarge-language-models-statistics-of-the-synthetic-data/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.