
This content originally appeared on HackerNoon and was authored by Anchoring
:::info Authors:
(1) Jianhui Pang, from the University of Macau, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab (nlp2ct.pangjh3@gmail.com);
(2) Fanghua Ye, University College London, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab (fanghua.ye.19@ucl.ac.uk);
(3) Derek F. Wong, University of Macau;
(4) Longyue Wang, Tencent AI Lab, and corresponding author.
:::
Table of Links
3 Anchor-based Large Language Models
3.2 Anchor-based Self-Attention Networks
4 Experiments and 4.1 Our Implementation
4.2 Data and Training Procedure
7 Conclusion, Limitations, Ethics Statement, and References
B Data Settings
To provide a thorough insight into how we continually pre-train the model into AnLLM and carry out evaluations, we showcase some data examples in this section for both training and testing data.
B.1 Training Data Examples
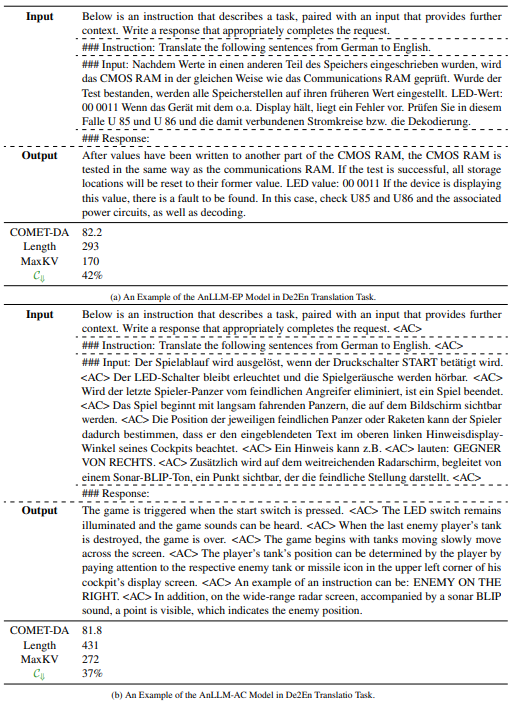
In this section, we provide examples to illustrate the specific data format used in training the AnLLM models. For the AnLLM-EP model, the endpoints act as anchor tokens, allowing us to directly utilize natural language texts. For the AnLLM-AC model, we append a new token at the end of each sequence in the input texts, which are initially split into sentences using the NLTK toolkits.[3] Some examples are presented in Table 6. All the trainig data are downloaded from HuggingFace [4], an opensource community.
B.2 Testing Data Examples
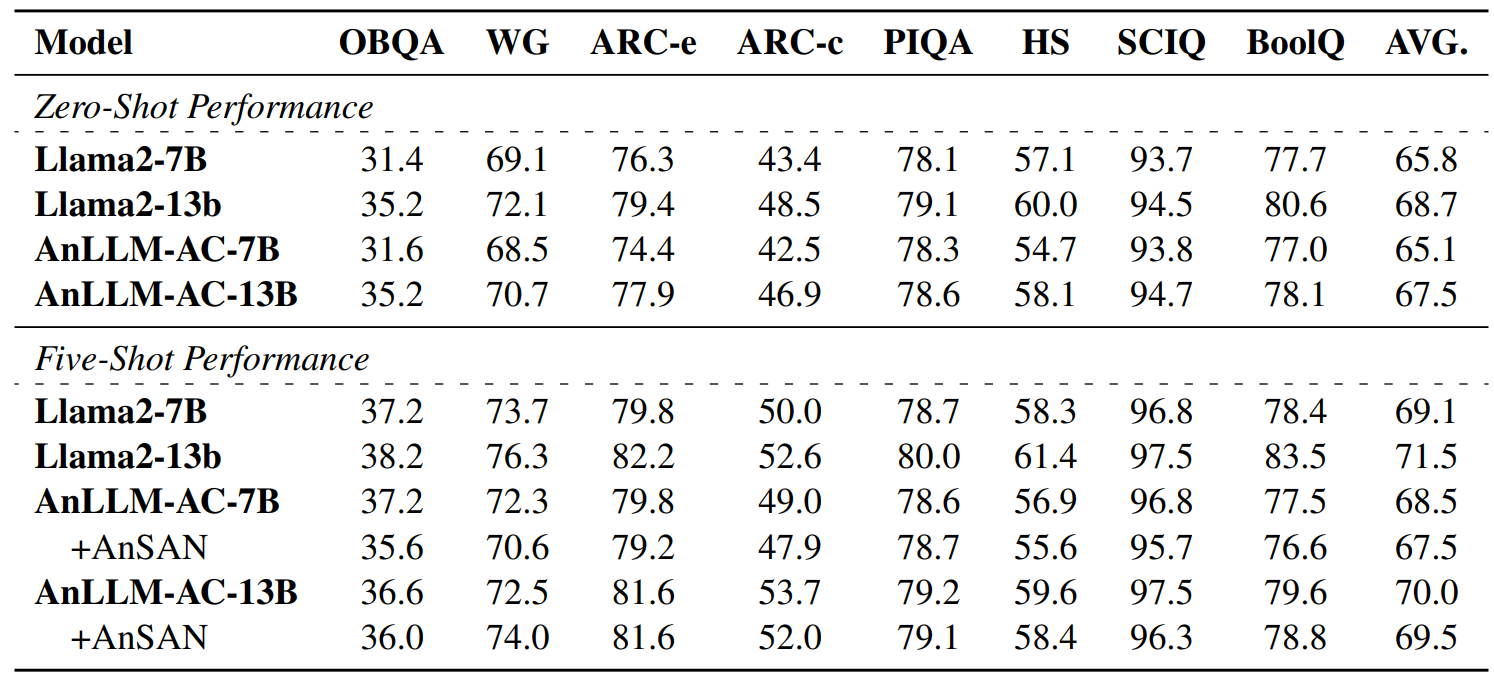
For the testing outlined in the results section (Section 5), we employ the same evaluation method as in previous work (Gao et al., 2023), which treats each choice as text generation and computes the corresponding probabilities, respectively. Table 7 presents some evaluation examples.
\

\
\
\

\

\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[3] https://www.nltk.org/api/nltk.tokenize.punkt. html
\ [4] https://huggingface.co/datasets/ togethercomputer/RedPajama-Data-1T-Sample
This content originally appeared on HackerNoon and was authored by Anchoring
Anchoring | Sciencx (2024-10-11T16:00:42+00:00) Training and Testing Data Formats for AnLLM Models. Retrieved from https://www.scien.cx/2024/10/11/training-and-testing-data-formats-for-anllm-models/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.